
Today, we’re announcing the release of a new artificial intelligence service designed to improve the way editors maintain the quality of Wikipedia. This service empowers Wikipedia editors by helping them discover damaging edits and can be used to immediately “score” the quality of any Wikipedia article. We’ve made this artificial intelligence available as an open web service that anyone can use.
Wikipedia is edited about half a million times per day. In order to maintain the quality of Wikipedia, this firehose of new content needs to be constantly reviewed by Wikipedians. The Objective Revision Evaluation Service (ORES) functions like a pair of X-ray specs, the toy hyped in novelty shops and the back of comic books—but these specs actually work to highlight potentially damaging edits for editors. This allows editors to triage them from the torrent of new edits and review them with increased scrutiny.
By combining open data and open source machine learning algorithms, our goal is to make quality control in Wikipedia more transparent, auditable, and easy to experiment with.
Our hope is that ORES will enable critical advancements in how we do quality control—changes that will both make quality control work more efficient and make Wikipedia a more welcoming place for new editors.
We’ve been testing the service for a few months and more than a dozen editing tools and services are already using it. We’re beating the state of the art in the accuracy of our predictions. The service is online right now and it is ready for your experimentation.
How it works
ORES brings automated edit and article quality classification to everyone via a set of open Application Programming Interfaces (APIs). The system works by training models against edit- and article-quality assessments made by Wikipedians and generating automated scores for every single edit and article.
What’s the predicted probability that a specific edit be damaging? You can now get a quick answer to this question. ORES allows you to specify a project (e.g. English Wikipedia), a model (e.g. the damage detection model), and one or more revisions. The API returns an easily consumable response in JSON format:

 |
“damaging”: { “prediction”: true, “probability”: { “false”: 0.0837, “true”: 0.9163 } } |
 |
“damaging”: { “prediction”: false, “probability”: { “false”: 0.8683, “true”: 0.1317 } } |
English Wikipedia revisions as seen by editors (left) and as scored by ORES’ “damage” prediction model (right).
We built the service to be scalable, easily extensible and responsive: you can retrieve a score in a median time of 50 milliseconds (for already scored revisions) to 100 milliseconds (for unassessed revisions). As of today, we support 14 language Wikipedias and Wikidata and we have computed scores for over 45 million revisions. You can get started and use revision scores in your application with just a few lines of code by calling one of the available ORES endpoints.
Towards better quality control
ORES is not the first AI to be designed to help Wikipedians to do better quality control work. English Wikipedians have long had automated tools (like Huggle and STiki ) and bots (like ClueBot NG) based on damage-detection AI to reduce their quality control workload. While these automated tools have been amazingly effective at maintaining the quality of Wikipedia, they have also (inadvertently) exacerbated the difficulties that newcomers experience when learning about how to contribute to Wikipedia. These tools encourage the rejection of all new editors’ changes as though they were made in bad faith, and that type of response is hard on people trying to get involved in the movement. Our research shows that the retention rate of good-faith new editors took a nose-dive when these quality control tools were introduced to Wikipedia.[1]
It doesn’t need to be that way. For example, ORES allows new quality control tools to be designed that integrate with newcomer support and training spaces in Wikipedia (like the Teahouse and the Help desk). Despite evidence on their negative impact on newcomers, Huggle, STiki and ClueBot NG haven’t changed substantially since they were first introduced and no new tools have been introduced. These dominant tools tightly couple damage-detection AI with problematic quality control practices that make the newcomer environment so harsh. By decoupling the damage prediction from the quality control process employed by Wikipedians, we hope to pave the way for experimentation with new tools and processes that are both efficient and welcoming to new editors.
A feminist inspiration
“Please exercise extreme caution to avoid encoding racism or other biases into an AI scheme.” –Wnt (from The Signpost)
When thinking about this problem, we were inspired by recent research that has called attention to increased technological influence on governance and power dynamics of computer-mediated spaces.[2] While artificial intelligence may prove essential for solving problems at Wikipedia’s scale, algorithms that replicate subjective judgements can also dehumanize and subjugate people and obfuscate inherent biases.[3] An algorithm that flags edits as subjectively “good” or “bad”, with little room for scrutiny or correction, changes the way those contributions and the people who made them are perceived.
Software development in a collaborative environment is a lot like a conversation—it requires the application of many different perspectives and progress happens through a sequence of iterations. Before we made the ORES scoring service available, it was extremely difficult to stand up a new tool that took advantage of an AI for damage-detection. By removing this barrier to entry, we’re adopting a “hearing to speech” strategy via open infrastructure. We’re betting that, by lowering barriers for tool developers, we’ll enable them to explore better strategies for quality control work—strategies that aren’t so off-putting to newcomers.
It’s not just the service that is open—our whole process is open. We’ve made revision scoring transparent and auditable by making the source code of the models, the underlying data, performance statistics and project documentation publicly available under open licenses. Revision scores themselves are released under a Creative Commons Zero (public domain) dedication for maximum reusability.
We look forward to hearing what you would use quality scores for in Wikipedia and how we could extend and further grow the project.
Who’s using revision scores
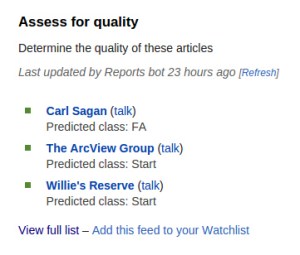
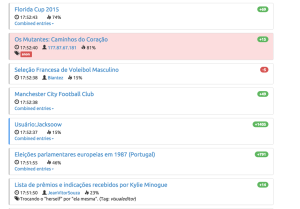
Examples of ORES usage. WikiProject X’s uses the article quality model (wp10) to help WikiProject maintainers prioritize work (left). Ra·un uses an edit quality model (damaging) to call attention to edits that might be vandalism (right).
Popular vandal fighting tools, like the aforementioned Huggle, have already adopted our revision scoring service. But revision quality scores can be used to do more than just fight vandalism. For example, Snuggle uses edit quality scores to direct good-faith newcomers to appropriate mentoring spaces,[4] and dashboards designed by the Wiki Education Foundation use automatic scoring of edits to surface the most valuable contributions made by students enrolled in the education program.
What’s next
We’re currently working on three different things to improve and expand the service:
- Supporting more wikis: Revision scoring already supports 3 different edit quality models (reverted, damaging, and goodfaith) and an article quality model (wp10). We currently support Wikidata and 14 different Wikipedia language editions (German, English, Spanish, Estonian, Dutch, Persian, French, Hebrew, Indonesian, Italian, Portuguese, Turkish, Ukrainian, Vietnamese) and we’re implementing support for more wikis as fast as we can. If ORES doesn’t already support your wiki, get in contact with us and we’ll let you know how you can help.
- Edit type classification: We’re working on a model to automatically categorize edits by the type of work performed. We believe an edit type model can be used to improve the design of edit histories, behavior analyses and recommender systems.
- Bias detection: Subjective predictions like those that ORES supports can perpetuate biases. We’re developing strategies for detecting bias in the models; our scores and fitness measures are freely available and we’re actively collecting feedback on mistakes.
Getting involved
There are many ways in which you can contribute to the project. Please see our project documentation, contact information, and IRC chatroom.
We’re currently looking for volunteers and collaborators with a variety of skills:
- UI developers (Javascript and HTML)
- Backend devs (Python, RDBMS, distributed systems)
- Social scientists (Bias detection, observing socio-dynamic effects)
- Modelers (Computer science, stats or math)
- Translators (bring revscoring to your wiki by helping us translate and communicate about the project)
- Labelers (help us train new models by labeling edits/articles)
- Wiki tool developers (use ORES to build what you think Wikipedians need)
Acknowledgments
Revision scoring is a joint effort by Wikimedia Research and several volunteers and researchers. The project wouldn’t have seen the light without generous support from the Individual Engagement Grants program and Wikimedia Deutschland, and contributions by the following individuals: Amir Sarabadani, Helder, Gediz Aksit, Yuvaraj Panda, Adam Wight, Arthur Tilley, Danilo.mac, Morten Warncke-Wang, and Andrew G. West.
Aaron Halfaker, Senior Research Scientist
Dario Taraborelli, Director, Head of Research
Wikimedia Foundation
Notes and references
- 1. Halfaker, A., Geiger, R. S., Morgan, J. T., & Riedl, J. (2012). The rise and decline of an open collaboration system: How Wikipedia’s reaction to popularity is causing its decline. American Behavioral Scientist, 0002764212469365. PDF https://dx.doi.org/10.1177/0002764212469365
- 2. Geiger, R. S. (2014). Bots, bespoke, code and the materiality of software platforms. Information, Communication & Society, 17(3), 342–356. PDF https://dx.doi.org/10.1080/1369118X.2013.873069
- 3. Tufekçi, Z. (2015). Algorithmic Harms beyond Facebook and Google: Emergent Challenges of Computational Agency. J. on Telecomm. & High Tech. L., 13, 203. PDF
- 4. Halfaker, A., Geiger, R. S., & Terveen, L. G. (2014, April). Snuggle: Designing for efficient socialization and ideological critique. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 311–320). ACM. PDF https://dx.doi.org/10.1145/2556288.2557313
All images in this article aside from the lead are screenshots by Aaron Halfaker, freely licensed under CC-BY-SA 4.0.




{kind=link}