
“لماذا تقرأ هذه المقالة اليوم؟”, “আপনি কেন এ নিবন্ধটি আজ পড়ছেন?”, “為什麼你今天會讀這篇條目?”, “Waarom lees je dit artikel vandaag?”, “Why are you reading this article today?”, “Warum lesen Sie diesen Artikel gerade?”, “?למה אתה קורא את הערך הזה היום”, “यह लेख आज आप क्यों पढ़ रहे हैं?”, “Miért olvasod most ezt a szócikket?”, “あなたは今日何のためにこの項目を読んでいますか?”, “De ce citiți acest articol anume astăzi?”, “Почему вы читаете эту статью сегодня?”, “Por qué estas leyendo este artículo hoy?”, “Чому Ви читаєте цю статтю сьогодні?”
This is the question we posed to a sample of Wikipedia readers across 14 languages (Arabic, Bengali, Chinese, Dutch, English, German, Hebrew, Hindi, Hungarian, Japanese, Romanian, Russian, Spanish, Ukrainian) in June 2017[1] with two goals in mind: to gain a deeper understanding of our readers’ needs, motivations, and characteristics across Wikipedia languages, and to verify the robustness of the results we observed in English Wikipedia in 2016. With the help of Wikipedia volunteers, we collected more than 215,000 responses during this follow-up study, and in this blog post, we will share with you what we learned through the first phase of data analysis.
First, why is understanding readers’ needs important?
Every second, 6,000 people view Wikipedia pages from across the globe. Wikipedia serves a broad range of the daily information needs of these readers. Despite this, we know very little about the motivations and needs of this diverse user group: why they come to Wikipedia, how they consume its content, and how they learn. Knowing more about how this group uses the site allows us to ensure that we’re meeting their needs and developing products and services that help support our mission.
Why didn’t we address this question earlier?
It’s incredibly hard to receive this kind of data at scale and we had to build our capacity to take in this kind of data. Over the past several years, we have laid the foundation for doing this kind of research. Starting in 2015, the Wikimedia Analytics team made the storage and analysis of webrequest logs possible. These logs, which are stored for 90 days, provide an opportunity for performing deeper analyses of reader behavior. However, analyzing actions can be difficult on a site at Wikipedia’s scale. Every second, we can easily receive 150,000 requests performed by readers when loading a webpage. Without knowing what kind of questions we want to answer or what reader characteristics we are interested in, the analysis of webrequest logs resembles the search for a needle in the haystack. The key to our puzzle came in 2015, with the arrival of the Wikimedia Foundation microsurvey tool QuickSurveys. Through QuickSurveys, we can create a framework for interaction with people using Wikipedia. For this study, we combined qualitative user surveys (via QuickSurveys) with quantitative data analysis (via webrequest logs) to make sense of our readers’ needs and characteristics.
What we learned
In 2016, we built the first taxonomy of Wikipedia readers, quantified the prevalence of various use cases for English Wikipedia, and gained a deeper understanding of readers’ behavioral patterns associated with every use case. (The details of the methodology are described in our peer-reviewed publication on this topic.) A year later, when we replicated this study and extended it to other language editions, we put the same survey questions from 2016 in front of readers across 14 languages. More specifically, we asked readers about
- Their information needs (Were they looking up a specific fact or to trying to get a quick answer? Getting an overview of the topic? or Getting an in-depth understanding of the topic?),
- Their familiarity with the topic (Were they familiar or unfamiliar with the topic they were reading about?), and
- The source of motivation for visiting the specific Wikipedia article on which they were shown the survey (Was it a personal decision, or inspired by media, a conversation, a current event, a work or school-related assignment, or something else?).
Below is what we have learned so far. (Note that all the results below are debiased based on the method described in the appendix of our earlier research to correct for various forms of possible representation bias in the pool of survey respondents.)
Information needs
“I am reading this article to (pick one) [look up a specific fact or get a quick answer, get an overview of the topic, or get an in-depth understanding of the topic]
The charts below summarize users’ information need across the 14 languages we studied.[2]

From these graphs, we see that on average around 35 percent of Wikipedia users across these languages come to Wikipedia for looking up a specific fact, 33 percent come for an overview or summary of a topic, and 32 percent come to Wikipedia to read about a topic in-depth. There are important exceptions to this general observation that require further investigation: Hindi’s fact lookup and overview reading is the lowest among all languages (at 20 percent and 10 percent, respectively), while in-depth reading is the highest (almost 70 percent). It is also interesting to note that Hebrew Wikipedia readers have the highest rate of overview readers (almost 50 percent).
Familiarity
“Prior to visiting this article (pick one) [I was already familiar with the topic, I was not familiar with the topic and I am learning about it for the first time]”
We repeat the same kind of plot as above, but now for the question that asked respondents how familiar they were with the article on which the survey popped up.
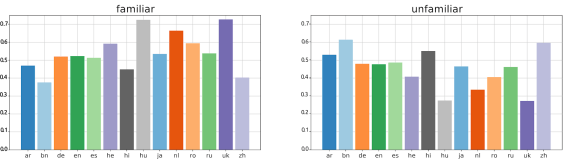
The average familiarity with the topic of the article in question is 55 percent across all languages. Bengali and Chinese Wikipedia users report much lower familiarity (almost 40 percent), while Dutch, Hungarian, and Ukrainian users report very high familiarity (over 65 percent). Further research is needed to understand whether these are fundamental differences between the reader behavior in these languages or whether such differences are the result of cultural differences in self-reporting.
Motivation
“I am reading this article because (select all that apply) [I have a work or school-related assignment, I need to make a personal decision based on this topic (e.g. to buy a book, choose a travel destination), I want to know more about a current event (e.g. a soccer game, a recent earthquake, somebody’s death), the topic was referenced in a piece of media (e.g. TV, radio, article, film, book), the topic came up in a conversation, I am bored or randomly exploring Wikipedia for fun, this topic is important to me and I want to learn more about it. (e.g., to learn about a culture), Other.]
Finally, we look at the sources of motivation leading users to view articles on Wikipedia.
These are the results:
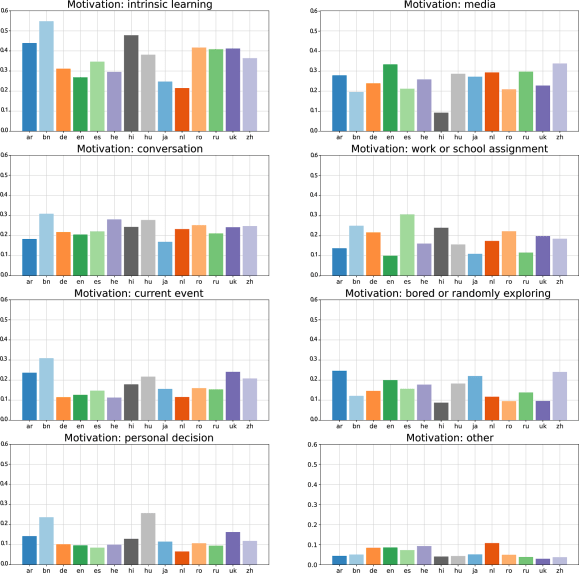
Among the seven motivations the users could choose from, intrinsic learning is reported as the highest motivator for readers, followed by wanting to know more about a topic that they had seen from media sources (books, movies, radio programs, etc.) as well as conversations. There are some exceptions: In Spanish, intrinsic learning is followed by coming to an article because of a work or school assignment; in Bengali by conversation and current event. Hindi has the lowest motivation by media score (10%), while Bengali has the highest motivation by intrinsic learning.
What can we conclude from this research?
We still need time to further analyze the data to understand and compare the behavior of users based on the responses above. We encourage careful examination of the above results, avoiding conclusions that the analysis may not support. Based on the above results we can confidently say a few things:
- Results of the survey for English Wikipedia are consistent with the 2016 results. (phew!) This could mean results for the other languages in the 2017 survey are also consistent over time. Follow-up studies will be needed to validate this.
- On average, 32 percent of Wikipedia readers come to the project for in-depth reading, 35 percent come for intrinsic learning, and both numbers can be as high as 55 percent for some languages. Wikipedia is a unique place on the Internet where people can dive into content and read and learn, just for the purpose of learning and without interruption. It is important for further content and product development to cherish this motivator and acknowledge the needs of the users to learn for the sake of learning.
- Media such as books, radio, movies, and TV programming play an important role in bringing readers to Wikipedia.
- We do see major differences in information need and motivation is languages, especially in the case of Hindi readers. Further research is needed to understand and explain such differences.
- The differences in reported numbers for familiarity with the content in Dutch, Hungarian, and Ukrainian Wikipedias can speak to fundamental differences in reader needs and behavior in these languages or cultural differences in self-reporting on familiarity. Further research is needed to shed light on these differences.
What’s next, and how can you help?
We have started the second phase of analysis for some of the languages. If you observe interesting patterns in the data in this blog post that you think we should be aware of and look into, please call it out. If you have hypotheses for some of the patterns we see, please call them out. While we may not be able to test every hypothesis or make sense of every pattern observed, the more eyes we have on the data, the easier it is for us to make sense of it. We hope to be able to write to you about this second phase of analysis in the near future. In the meantime, keep calm and read on!
Florian Lemmerich, RWTH Aachen University and GESIS – Leibniz Institute for the Social Sciences
Bob West, École polytechnique fédérale de Lausanne (EPFL) and Research Fellow, Wikimedia Foundation
Leila Zia, Senior Research Scientist, Wikimedia Foundation
———
Acknowledgements
This research is a result of an enormous effort by Wikipedia volunteers, researchers, and engineers to translate, verify, collect, and analyze data that can help us understand the people behind Wikipedia pageviews and their needs. We would like to especially thank the Wikipedia volunteers who have acted as our points of contacts for this project and helped us with the translation of the survey to their languages, going through the verification steps with us, and keeping their communities informed about this research.
———
Footnotes
[1] The choice of the languages for this study is the result of the following considerations: We ideally wanted to have at least one language from each of the language families as part of the study, and wanted to find languages that where the language communities welcome this study in and support us. We chose the following languages: Arabic (Right-to-left, covers large parts of the Middle East and North Africa), Dutch (per Wikimedia Netherlands request), English (to repeat the results from the initial survey), Hindi (at New Readers team’s request), Japanese (One of the CJKV languages that we know very little about despite the high traffic the language brings to Wikimedia projects), Spanish (a Romance language which helps us understand South America users and their needs to a good extent). 2. All the other languages we added after at least one person from their community responded to our call on the Wikimedia-l mailing list with interest.
[2] The language codes used in the plots are as follows: ar (Arabic), bn (Bengali) , zh (Chinese), nl (Dutch), en (English), de (German), he (Hebrew), hi (Hindi), hu (Hungarian), ja (Japanese), ro (Romanian), ru (Russian), es (Spanish), uk (Ukrainian).




{kind=link}