
A few days ago, my team completed the launch of “page previews”—a feature now deployed to hundreds of language editions of Wikipedia. We are seeing up to half a million hits every minute to our API to serve those cards that show when you hover over any link.
On the surface it looks quite simple. It’s something many websites have already. It has an image and some text and shows when you hover over a link. Hardly groundbreaking stuff … or so it may seem.
The original idea was conceived four years ago, based on an idea from a volunteer/editor many years before that.
It’s thus taken a few years for us to get this out to everyone. That might seem strange, but like an iceberg, once you start looking below it, it all makes sense.
We had to choose a thumbnail
We have several millions of pages, all stored as raw wikitext. We couldn’t expect every single article to be edited to designate a thumbnail.
Way back in 2012, Max Semenik, a software engineer on our Community Tech team, built an extension that would algorithmically work out the most appropriate image for an article.
As with all algorithms, it wasn’t perfect and since it wasn’t designed for the use case of page previews, it also required tweaking.
We had to make updates to limit the image to the first section of the article. Working with algorithms is hard, but for this purpose essential.
We had to generate a summary
We have several millions of pages, all stored as raw wikitext. How to summarise that without asking our editors to go in and painstakingly do that for every article?
The busy Max Semenik who helped us with the thumbnails, also wrote an extension to generate extracts of articles. It was originally written primarily for plain text summaries. Our initial versions of page previews used this, but we realised it wasn’t the best fit for what we were trying to do.
So we stopped using this.
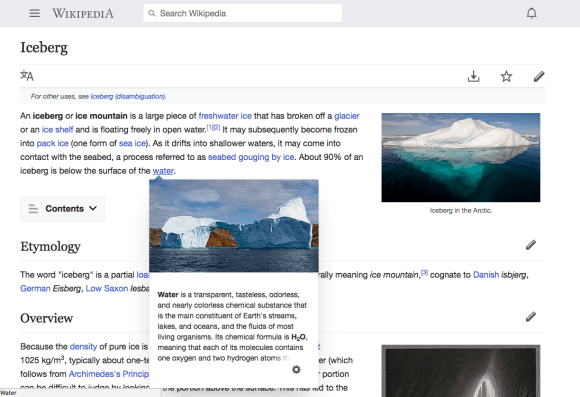
We realised HTML was very important. For instance chemistry articles featured chemical formulae which needs subscript which requires HTML.

Consider how HTML is needed to generate summaries for content where subscript is important such as the chemical formula of water, shown here. Text from the English Wikipedia article on water, CC BY-SA 3.0; image by Kim Hansen, CC BY-SA 3.0.
Many of our articles, begin with location information and pronunciation information. A lot of this content didn’t belong in our summaries and for other content it was less clear what belonged. The summaries had a lot of design input and we identified which content shouldn’t appear inside a preview. We wrote up a specification capturing the required behaviour.

Location information features at the beginning of many articles proving problematic for summarising Wikipedia articles…

… as does pronunciation information.
In the end we decided to build on top of an API that was originally built for our native Android and iOS apps. We created a new API specifically for this purpose.
We now generate the summary from the entire article HTML. We parse it just like a browser and per the specification identify the first “non-empty” lead paragraph of every article.
One of the big challenges here, was the decision to strip content inside parentheses. Since we support over 300 languages this had to be localised (not everyone uses the same character set!).
Not only that, but of course some parentheses are vital… edge cases are everywhere. We had to think about all their potential usage and how best to do them.
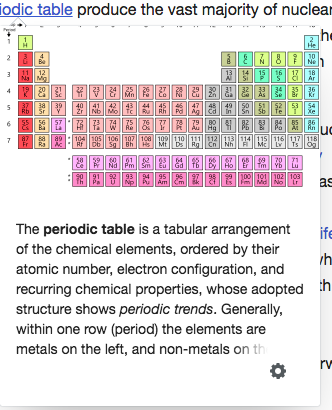
Sometimes content inside parentheses is important, as this example suggests. Identifying when they are important is hard. Text from the English Wikipedia article on the periodic table, CC BY-SA 3.0; image by Offnfopt, public domain.
Stripping parenthetical elements from user-generated HTML also turned out to be quite difficult. Whereas doing so in plain text requires a simple regular expression, things get more complicated when you consider nested HTML.
It was important to ensure the content continued to make sense with the content inside parentheses stripped and that we that we didn’t add any security vulnerabilities.
Thanks go to our Infrastructure team for helping us build out this API.
We work with our community
Our editing community cares a lot about our product. That’s why they write articles for you in their spare time for no monetary gain.
We include them in every part of the process, working with them tirelessly to fix every edge case (whether it be broken summaries, or inappropriate images) and to reassure them we know what we are doing, the impact of why we are doing and why we are continuing to do it.
Our initial version wasn’t good enough. Our community asked us not to go ahead with it. We answered by listening to them and making it better.
Thank you community and our community liaisons who helped facilitate those conversations!
Design design design
We did a lot of it. Our designer, Nirzar did a great write up so I won’t bother sharing any more here, but design was at every step of the process whether it was the initial prototypes (thanks Prateek Saxena!); discussing performance of the feature with our performance team; perfecting thumbnails and summaries; or talking to our community.
Thank you design team!
We had to instrument it
This was a big change to how people interact with our content. We care a lot about privacy in Wikimedia. We are likely to be one of the few (only?!) major websites who don’t install third party scripts to track you.
Our privacy policy forbids us from giving away data about you.
We don’t use vendors to A/B test or analyse our user’s behaviour.
Yet, despite all this, we don’t cut corners.
We don’t want to make dumb risky changes.
Every time we build something major we have to build out the infrastructure to evaluate it. We construct hypothesizes and tests to test those hypothesizes. We build it. We test it. We listen to the data. We adapt. We test again.
This means we juggle being a product team and an analytics team. Our development team wear multiple hats. Given the scale we work at have to deal with bugs. Occasionally, we find major bugs in browser vendors.
Our final A/B test by Tilman Bayer gave us many answers. It’s a great read!
Given the findings of that A/B test we also decided to start measuring “page preview views” as an additional metric to page views. That metric is firing 1000 events per second and our analytics team is kicking ass dealing with that sort of scale.
Thank you analysts, thank you analytics team!
We had to scale our API to support you
We are seeing 0.5 million hits to our API a minute.
We are seeing 0.5 million hits to our API a minute.
I say that twice because that’s a high volume of traffic.
Our traditional APIs were originally built for bots to help clean up your edits. They weren’t designed for readers.
The Wikimedia services team has been vital to the success of this project by providing the infrastructure to deal with, dealing with a lot of the caching (we rely heavily on Varnish) and making sure when content gets edited new summaries get generated. It’s well known that cache invalidation is one of the harder Computer Science problems.
Thank you services team!!
Thank you thank you thank you
Shipping something always feels good. I hope the “simple” preview my team with the help of many teams across the Wikimedia Foundation has shipped enriches your experience.
Lot’s of us have obviously been involved and we’re proud of what we’ve put out.
We’re not done. Software is never done.
We have code to clean up and new ideas for how to grow this small little feature.
Some might say we’re only seeing the tip of the iceberg.
———
The Wikimedia Foundation is a non-profit and relies on donations from people like you to keep the site up and running in such a way that it lives up to our values. To help us continue to build features like this, please consider donating to us.
Jon Robson, Senior Software Engineer, Desktop & Mobile Web
Wikimedia Foundation
Want to learn more? See the original announcement and how we designed page previews.
This post originally appeared in “Down the rabbit hole,” our Medium publication, and was modified for re-publication on the Wikimedia blog. Both posts have since been edited to fix a typo—our API is receiving half a million hits per minute, not five thousand.




{kind=link}
{kind=link}